




| Генетический алгоритм. Шаг 21. Обучаем нейросеть |

|

|
| Автор megabax | ||
| 28.10.2011 г. | ||

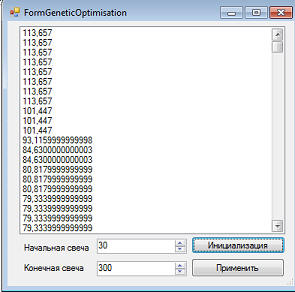
Генетический алгоритм. Шаг 21. Обучаем нейросетьИ так, я разработал скелет блока обучения нейросети. Скелет в том смысле, что пока он создает только начальную популяцию, получаемую путем случайной мутации первичных настроек нейросети. Для предварительных экспериментов этого пока достаточно. И так, доходной нейронной сети без оптимизации за период с 07.03.2006 по 06.04.2007 -3%. Генерируем начальную популяцию (200 особей):
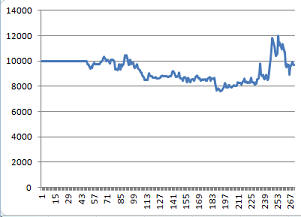
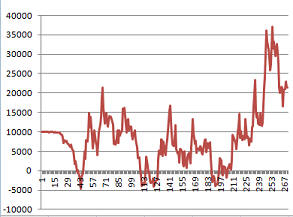
Лучшая доходность 113%, но радоваться рано, надо еще посмотреть, за счет чего получился такой результат и повториться ли он на более позднем интервале. Не подогнано ли под историю? И так, давайте сравним графики стоимости портфеля до и после оптимизации: До:
После:
Как видим из графика, просадка тоже возросла. При чем не хило. По суди дела, увеличение доходности было достигнуто просто за счет того, что график доходности "увеличился в размерах". Выросла доходность, выросла и просадка. Почему так получилось? В результате оптимизации нейросеть стала чаще подавать сигналы. А вот их качество нисколько не улучшилось, скорее наоборот, ухудшилось. Примерно такая же картина может произойти и на более близкой к реальности виртуальной бирже, когда я доработаю механизм контроля маржин колла и стопы. В общем, я пока вижу только один выход из создавшегося положения: надо доработать целевую функцию, сейчас она учитывает только доходность (собственно говоря, доходность это и есть целевая функция), а нужно, еще и учитывать просадку. Вопрос: как? Есть несколько вариантов:
Какой же метод самый лучший? Допустим, мы пошли по первому пути. Установили макс. просадку 30%. Если будет 29%, то особь "выживет". Далее, что у нас получиться при естественном отборе? Особь, дающая доходность 100% и просадку 5%, окажется худшей, по сравнению с особью, дающую доходность 101% и просадку 20%. Но ведь это не так! Я лично предпочел бы торговать по первой стратегии. Так что посмотрим в сторону второго варианта. Как в этом случае будет происходить отбор? Стратегия с большой доходностью и с большой просадкой окажется так же мало жизнеспособной, как особь с малой просадкой и малой доходностью. Что правильно: обе эти стратегии непривлекательный. А вот наверх поднимутся особи с большим значением доходности и малой просадкой, что нам и нужно. С другой стороны, через наш фильтр проскочит стратегия с большой просадкой и астрономической доходностью. А этого нам не надо: такая стратегия не больше, чем игра случайностей и вряд ли она имеет право на жизнь. Подобные "глюки" можно отсечь, комбинируя первый подход со втором. А еще лучше сделать вот такую зависимость: FinalFunc=income*K1-K4*eK2*drawdown+K3. Тогда при увеличении просадки привлекательность стратегии будет падать по экспоненте и нам даже не понадобиться вводить ограничение на максимальную просадку. Для начала я поставил вот такие коэффициенты:
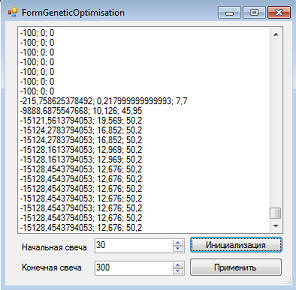
Доходность и просадка у меня в программе заданы в единице от начального значения, если перевести в %, то получиться k1=1; k2=0.1; k3=0; k4=1; В результате первоначального заполнения на первом месте оказались стратегии, где не совершенно вообще никаких сделок (в таблице на 1-ом месте целевая функция, на втором доходность %, на третьем просадка, %):
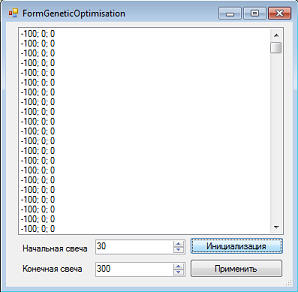
Везде просадка оказалась больше, чем итоговая доходность:
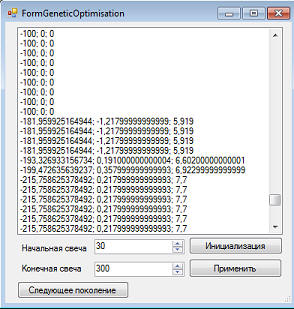
Посмотрим теперь, что будет если попытаться перейти к следующему поколению:
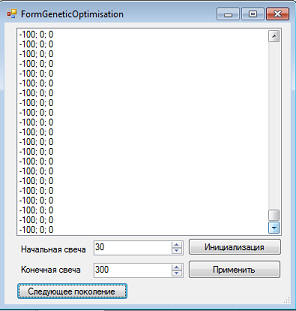
Как видим, по прежнему где то в хвосте маячат стратегии, которые совершали какие либо сделки. Жмем кнопку "Следующее поколение" еще раз. Все торгующие вымерли. Остались только те, что не совершили ни одной сделки:
Выход из положения: правильно подобрать коэффициенты, а так же поэкспериментировать с изменением вероятности мутации и скрещивания. Но это уже следующий шаг. |
||
| Последнее обновление ( 28.10.2011 г. ) | ||
| « След. | Пред. » |
|---|


