




| Моделирование сознания. Урок 11. Новые стратегии поведения. |

|

|
| Автор megabax | |||||
| 14.04.2024 г. | |||||
|
Моделирование сознания. Урок 11. Новые стратегии поведения. Что бы смотреть урок полностью и скачать исходники, подпишитесь на платный раздел. В платном разделе статья находиться здесь. В прошлой статье было описано создание модуля поиска пищи и избегания опасностей. Сейчас будем улучшать эти модули. Начнем с модуля избегания опасностей. В класса DangerAvoiding добавим поле lock_threahold:
Это поле нужно для функции, которая будет определять а не заперт ли робот. Она будет сравнивать сигналы сенсоров с этим порогом, если хоть один сенсор показал значение ниже - есть куда идти:
Что будет делать робот в противном случае? Ломать стены, он это может, если их прочность менее 1. Но если ломать стену не надо (на это тратится энергия) то робота надо остановить, если он движется к стене. Для этого предусмотрим вот этот метод: ... ... Теперь займемся блоком поиска еды. Пусть робот ищет где подзарядиться не случайным блуждаем, а двигаясь по спирали. Если наткнется на стену, то некоторое время ищет случайным блужданием, затем снова запускает с самого начала движение по спирали. Если мы хотим реализовать такой алгоритм, то нам не нужно удалять стратегию случайного блуждания, надо лишь выделить ее в отдельный модуль. Для этого отдельного модуля мы создадим класс, который назовем RandomWalk. но так как у нас будет не одна стратегия поведения, то логичнее сделать у всех стратегий общий класс предок, назвав его, например, Behavior:... ... ... И также внесем изменения в метод step():
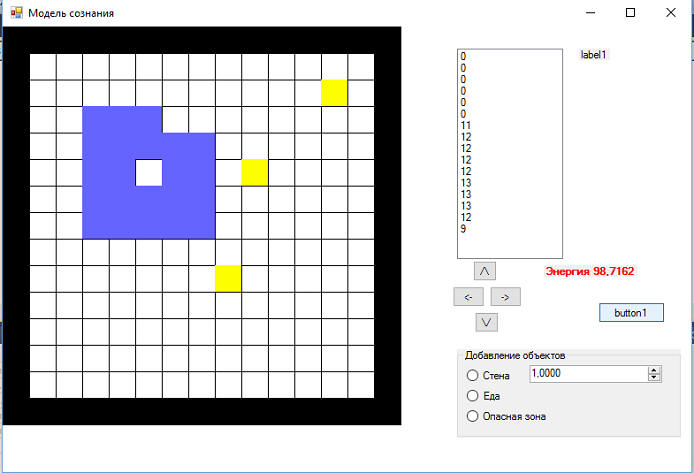
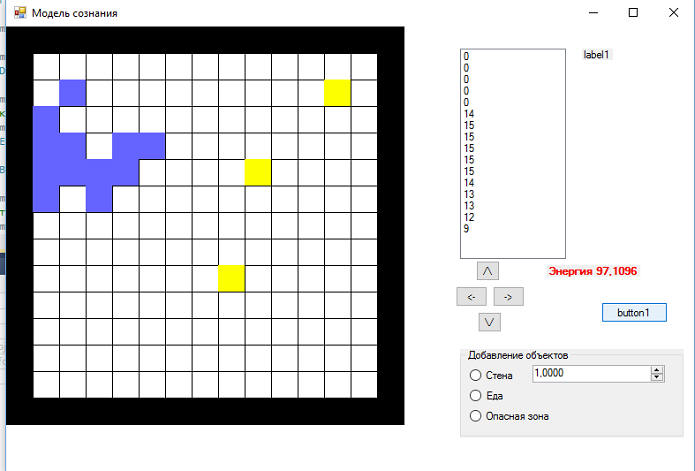
Все, теперь мы можем протестировать:
сравним со случайным блужданием:
Итак, стратегии поведения "случайное блуждание" и "движение по спирали" реализованы и протестированы. Теперь займемся алгоритмом поиска еды, класс FoodSearcher. К нему мы добавим ряд полей: ... ... ... ... и изменим конструктор:
Также придется переделать у него и метод step(): ... ... ... ... Поведения робота стало чуть-чуть более интеллектуальным. Однако, как показали испытания, данный алгоритм в условиях, когда вокруг много препятствий и мало еды, достаточно далек от оптимального: очень часто робот переходит в режим RandomWalk и все начинает с сначала. Но улучать мы его будет уже в следующих уроках. |
|||||
| « След. | Пред. » |
|---|


