




| Эксперименты с синтетическими котировками. Статья 2. Эксперимент с обучением нейросети |

|

|
| Автор megabax | |
| 08.11.2012 г. | |
Эксперименты с синтетическими котировками. Статья 2. Эксперимент с обучением нейросетиИсходник используемого в уроке советника можно скачать в платном разделе. См. так же анонсы исходников. В прошлой статье мы создали синтетически котировки. А сейчас опишу эксперимент с обучением торговле на этих котировках простейшей нейронной сети, состоящей из одного персептрона. Если сеть сможет самообучаться торговать на идеальных синтетических котировках, то я в следующий раз подсуну ей задачу посложнее, затем еще сложней, потом еще и в конце концов заставим торговать на реальных котировках. И так, ход эксперимента. Я создал простейшего советника на персептроне, метод обучения которого можно свести к формуле: dw=mu*(t-y)*x(u) где dw - вектор изменения весов коэффициентов, t - желаемая реакция нейрона, y - реальная реакция нейрона, x(u) - входной вектор, mu - коэффициент обучения. В качестве входных данных я взял ценовые поля (open, high, low, close) 5-ти свечей, предшествующих текущей. Если результат суммирования всех входов, помноженных на весовые коэффициенты, выше пороговой величины, то это сигнал на покупку (значение персептрона +1), если меньше - это сигнал на продажу (значение персептрона -1). Советник открывает позицию по сигналу без стопов, при приходе противоположного сигнала закрывает ордер и открывает новый по сигналу (переворачивает позицию). Обучение персептрона происходит каждый раз, когда equity ниже предыдущего. Значение весовых коэффициентов инициализируются случайными числам, начальное пороговое значение - нуль. Диапазон тестирования с 01.12.2011 по 05.11.2012, на пятиминутных таймфреймах. Таким образом, в теории нейросеть должна "выучить" когда ей выгодно покупать, а когда продавать. Напоминаю, что пока я производил эксперименты с синтетическими котировками, полученными в рамках предыдущей статьи. А как обстоят дела на практике? А на практике оказалось непонятно как выбрать коэффициент обучения. Поэтому я решил выбрать его эмпирическим путем. Сначала проверил пять обучение с mu=0.001 для пяти разливных псевдослучайных инициализаций весовых коэффициентов: вариант 1:
вариант 2:
вариант 3:
вариант 4:
вариант 5:
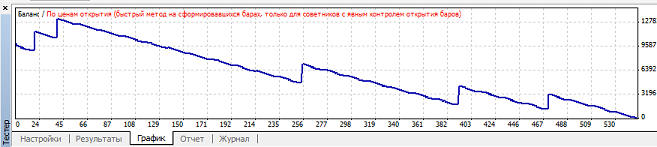
Как видим, ни в одном из пяти случаем обучение не происходит, советник сливает депозит. Видим, я взял слишком маленький коэффициенто обучения, надо поробовать больше. Поэтому следующий эксперимент я проводил для mu=0.01: вариант 1:
вариант 2:
вариант 3:
вариант 4:
вариант 5:
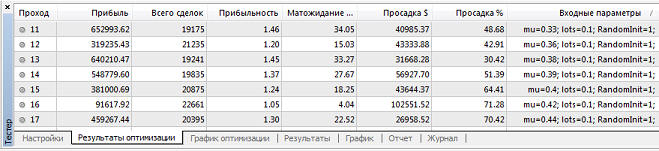
Обучение не просиходит. Тогда я принимаю решение применить оптимизацию. Для каждого из пяти вариантов, диапазон mu от 0.01 до 1, шаг 0.01. Вариант 1. Нейросеть обучается при mu>=0.21, но в зависимости от коэффициента обучения размер прибыли, профит фактора и просадки сильно варьируется:
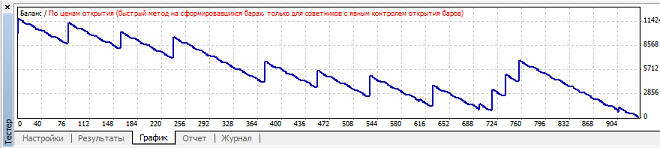
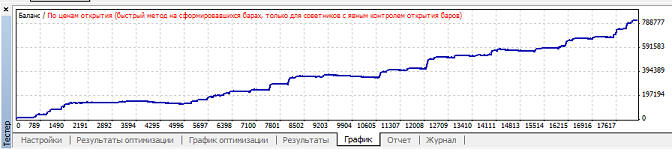
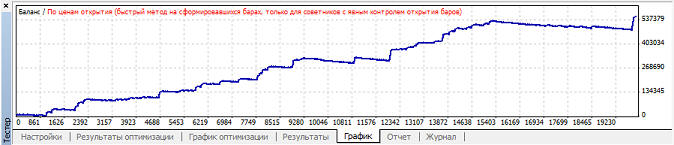
Наибольшая прибыль при mu=0.85, при этом кривая баланса имеет вот такой вид:
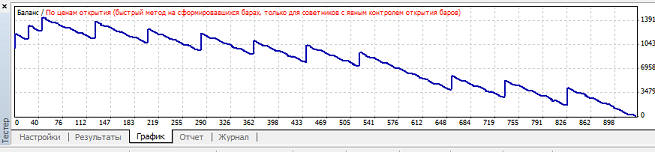
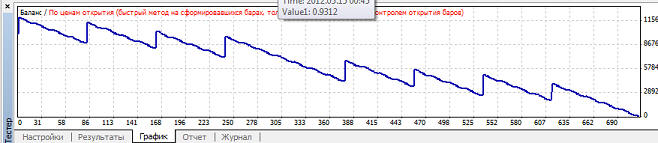
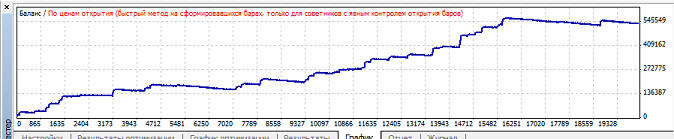
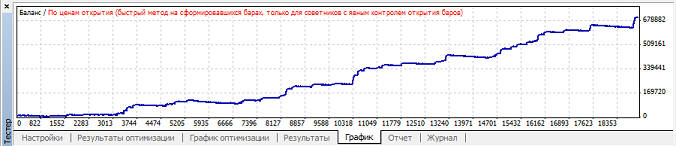
Наибольший профит фактор так же при mu=0.85. Наименьшая просадки при mu=0.97, график баланса имеет вот такой вид: Вариант 2. Нейросеть обучается при mu>=0.82, но в зависимости от коэффициента обучения размер прибыли, профит фактора и просадки сильно варьируется: Наибольшая прибыль при mu=0.88, при этом кривая баланса имеет вот такой вид:
Наибольший профит фактор так же при mu=0.88. Наименьшая просадки при mu=0.92, график баланса имеет вот такой вид:
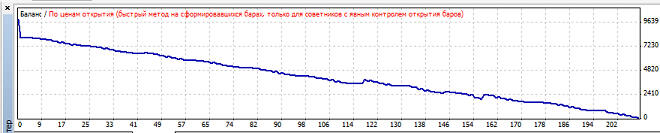
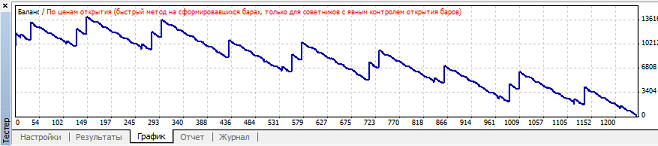
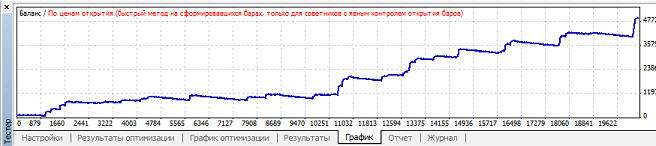
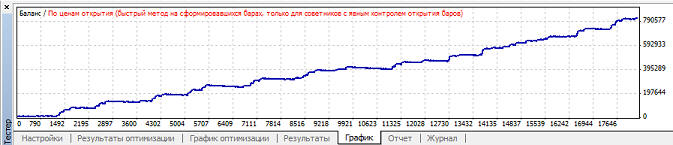
Вариант 3. Нейросеть обучается при mu>=0.64, но в зависимости от коэффициента обучения размер прибыли, профит фактора и просадки сильно варьируется: Наибольшая прибыль при mu=0.8, при этом кривая баланса имеет вот такой вид:
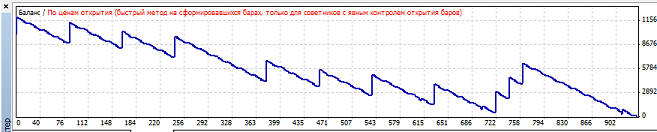
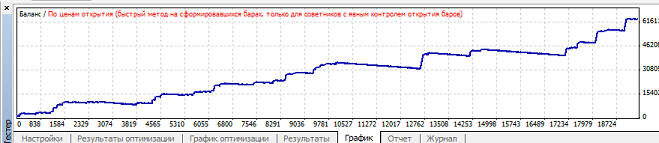
Наименьшая просадки при mu=0.8, так как mu точно такой же, то график уже не привожу, он так же будет точно такой же. Вариант 4. Нейросеть обучается при mu>=0.45, но в зависимости от коэффициента обучения размер прибыли, профит фактора и просадки сильно варьируется: Наибольшая прибыль при mu=0.51, при этом кривая баланса имеет вот такой вид:
Наименьшая просадки при mu=0.51, так как mu точно такой же, то график уже не привожу, он так же будет точно такой же. Вариант 5. С данным диапазоном оптимизация не получилась. Тогда я стал оптимизировать до mu=2. Нейросеть обучается при mu>=1.78, но в зависимости от коэффициента обучения размер прибыли, профит фактора и просадки сильно варьируется:
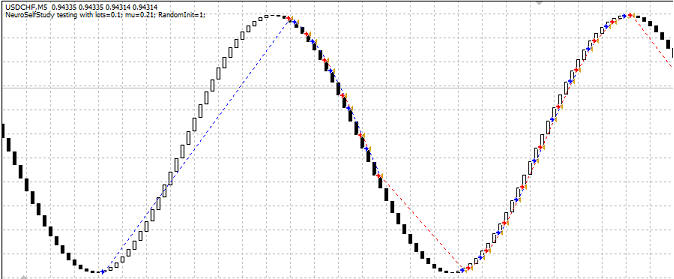
Наименьшая просадки при mu=1.78, так как mu точно такой же, то график уже не привожу, он так же будет точно такой же. Анализ обучения. Далее, я решил посмотреть, как же проходит обучение нейронной сети. Начал с варианта 1:
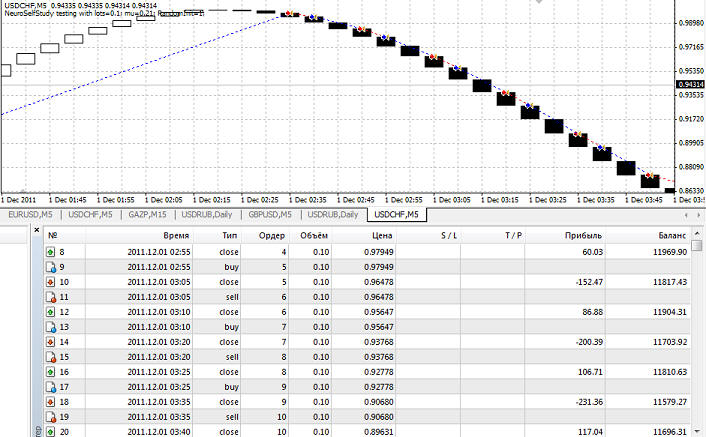
Как видно из графика, первая сделка - это покупка. Закрылась она очень хорошо, хотя сеть еще и не была обучена. Это видно хотя бы потому, что далее пошлы уже "глупые" сделки, которые не приносили прибыль:
Затем пошла прибыльная сделка на продажу:
Но после чего пошли "плохие" сделки на росте, за которыми последовала идеальная сделка на падении:
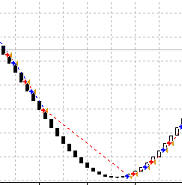
Что же у нас получилось? Нейросеть разучилась делать деньги на росте, но зато научилась на падении. А затем нейросеть вообще разучилась торговать:
Затем нейронная сеть заново научилась делать деньги на падении:
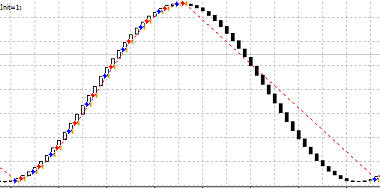
После чего достаточно долгое время нейронная сеть то разлучалась торговать, то снова обучалась (на падении). Но однажды снова научилась делать прибыль на росте и даже на падении:
Но потом опять пошли циклы: нейросеть то разучиться торговать, то снова научиться делать прибыль на падении. Затем однажды было несколько "волн", где сеть прибыльно торговала на повышении, после чего опять то же самое. А потом взяла и резко научилась делать прибыль и на падении и на повышении:
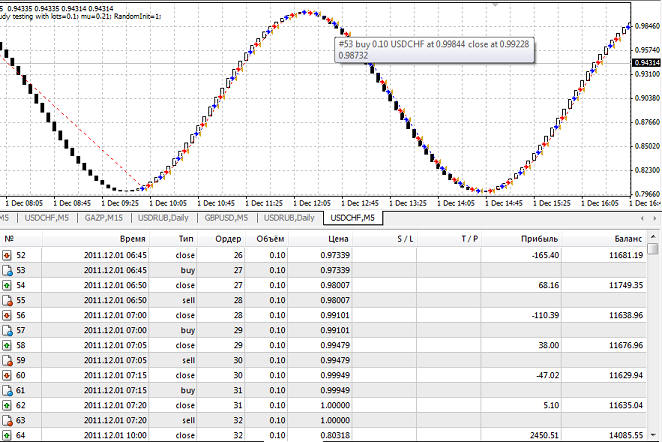
Затем сеть снова разучилась торговать, после чего опять пошли циклы: "глупые сделки" -> "прибыль на падении" -> "глупые сделки" -> "прибыль на падении" -> ... Затем нейронная сеть снова научилась торговать и на этот раз на большее число волн. Но потом опять разучилась:
В общем, при дальнейшем просмотре сделок я заметил следующую закономерность: сеть обучается, потом наоборот, торгует хуже. Затем снова обучается. и там много раз, но с каждым разом обучение происходит более качественно: полученных навыков с каждым разом хватает все на большие и на большие промежутки времени. Просмотр остальных вариантов показал те же самые закономерности. Напрашивается следующий эксперимент: а что если уменьшать mu, когда сеть уже обучилась? Но это уже тема следующего шага.
Скриншоты, опубликованные в данной статье, являются цитатами и иллюстрациями программного продукта "Metatrader 4", авторское право на который принадлежит "MetaQuotes Software Corp".
|
|
| Последнее обновление ( 15.05.2013 г. ) |



| « След. | Пред. » |
|---|


